 夏2同学的个人小站
夏2同学的个人小站
前言
最近在学习python爬虫,在对数据进行持久化存储的时候,会选择使用json格式的数据进行存储,由此就引发了一个问题,python中的JSON库到底咋用?

以前使用JavaScript中Json.stringfy和Json.parse倒是用的飞起。
到了python中使用json库就不会用了,这不行!!!
必须解决这个问题,由此,经过学习后,就产生了下文。
内容
简介
JSON是一种轻量级的数据交换格式。
核心方法
python中的json库核心方法只有4个
- json.dump
- json.dumps
- json.load
- json.loads
dump在计算机英语中是 转存、导出、保存 的意思
那么就很好理解了。
dumps ,拆解开来,dump string , 转化为字符流的数据
现在,我们来看一段代码:
dic = {
'name': 'tom',
"age": 18,
"friends": (
'mick',
'jerry'
),
'text': 'hello world'
}
# obj --> json
res = json.dumps(dic)
print(res)
# 结果:
# {"name": "tom", "age": 18, "friends": ["mick", "jerry"], "text": "hello world"}json中字符串对应的使用的是双引号,所以 python中的 ‘name’ 变成了 "name"
python中tuple对应的是json中的arr,所以出现了以下变化,( 'mick', 'jerry' ) --- >["mick", "jerry"]
那么接下来我们试试dump的操作。
dump的操作实现的功能是将python对象转化成json数据并存储到文件中。
dic = {
'name': 'tom',
"age": 18,
"friends": (
'mick',
'jerry'
),
'text': 'hello world'
}
fp = open('./dic.json', 'w', encoding='utf-8')
# obj --> json 并且将json写入文件
json.dump(dic, fp, ensure_ascii=False)
# fp = file place 作用是指定文件位置和读写方式运行这段代码后,自然就会生成 dic.json的文件,内容如下所示
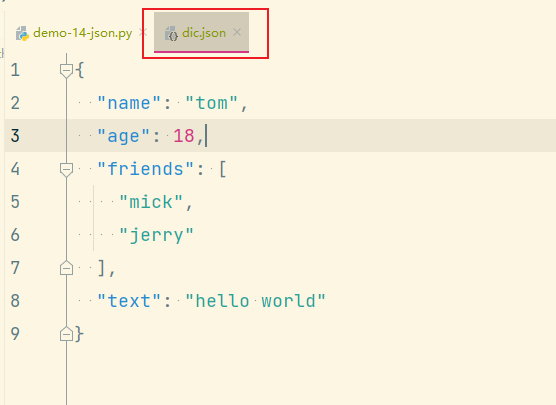
load的含义是加载,通过上面的学习,可以以此类推 load 和 loads方法。
dump , 将python对象转换成json数据,并向文件中保存json数据。
load,从文件中读取json数据,并转化成python对象。
dumps,python字符流转化成 json数据流, 简单的讲,python obj --- > json
loads, json数据流 加载成python字符流,简单的讲,json---> python obj
下面是一组实例:
使用json.loads方法:
# 这是一个json格式的字符串
json_text = '{"name": "tom", "age": 18, "friends": ["mick", "jerry"], "text": "hello world"}'
# loads = load from string
res = json.loads(json_text)
print(res)
# 结果:{'name': 'tom', 'age': 18, 'friends': ['mick', 'jerry'], 'text': 'hello world'}
print(type(res))
# 结果: <class 'dict'>使用json.load方法:
fp = open('./dic.json', 'r', encoding='utf-8')
# 从文件中读取json数据
res = json.load(fp)
print(res)
# 结果:{'name': 'tom', 'age': 18, 'friends': ['mick', 'jerry'], 'text': 'hello world'}
print(type(res))
# 结果:<class 'dict'>dic.json数据如下:
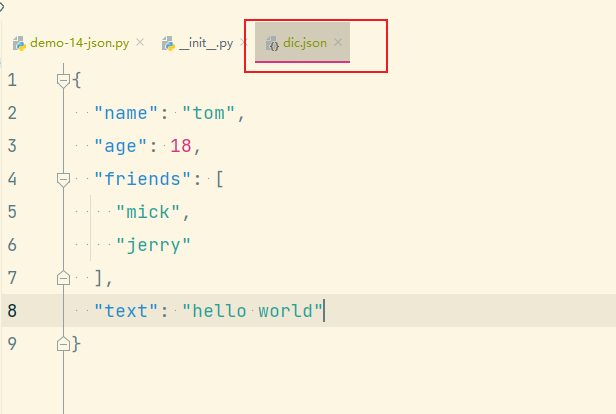
总结
可以简单的理解,loads, 加了s就是从字符流中加载,不加s就是从文件流中加载。
所以json.load(fp) , 第一个参数fp指定的是文件的位置,同时fp是必传参数,不传就报错。
dump和dumps同理。
特别注意:
需要特别注意的是dump在对中文进行保存的时候,中文会被默认转化成unicode编码
fp = open('./dic.json', 'w', encoding='utf-8')
# 张三 --- > "\u5f20\u4e09" 默认中文会被转化成Unicode编码
dic = {
'name': '张三',
'age': 18
}
json.dump(dic, fp)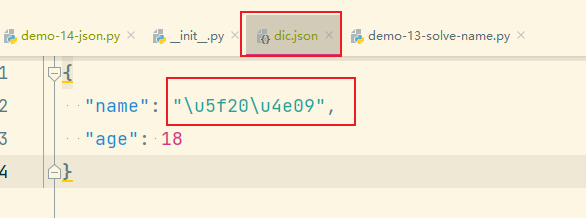
运行后,可以明显感受到 中文变成了Unicode编码,解决办法。
添加关键词,ensure_ascii=False ,这样就不会自动转化成Unicode编码了。
fp = open('./dic.json', 'w', encoding='utf-8')
# 张三 --- > "\u5f20\u4e09" 默认中文会被转化成Unicode编码
dic = {
'name': '张三',
'age': 18
}
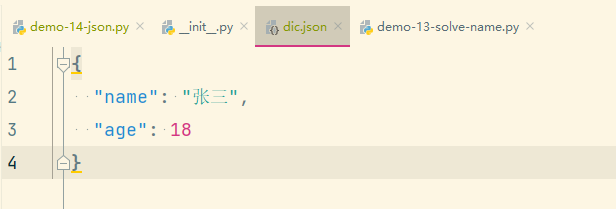
# 这里加了 ensure_ascii=False
json.dump(dic, fp, ensure_ascii=False)此时中文就能正常显示了。
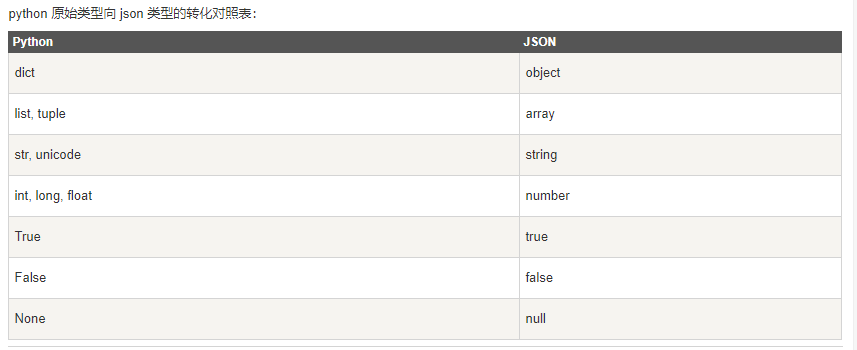
附1:python和json对照表
作者信息
@author: 夏2同学 @time: 2021年1月20日 @title: python中的JSON到底怎么用?